嗨大家(如果有人在看的話)~前兩天介紹了一些python資料處理的基本用法,介紹的都是python內建的函式,但其實python的價值絕對不止於這些內建的東西。我們還可以像多功能攪拌器一樣,幫它裝上不同的頭,讓它做不一樣的事。而從別的地方把頭裝到攪拌器上面在python裡面就是所謂的套件引入。這些套件裡面也別人幫我們寫好的函式可以幫我們更有效率地做事。所以今天的第一個部分就是要教大家怎麼在colab下載套件並把它們引入。
接下來就以math跟今天會使用到的套件pandas來示範。其實作法很簡單啦,就分成安裝跟引入兩行程式碼而已。首先是安裝的部分。
!pip install math
!pip install pandas
執行之後沒有出現error code就沒問題。
成功安裝之後就可以請他進來了。
import math, pandas
就是這麼簡單。如果要使用套件裡面的函式,只要把套件名稱加上點跟要使用的函式就可以了。
# 用math裡面的fabs取絕對值
math.fabs(-7)
# 輸出
7
但是套件那麼多,有的名字還很長,每次都要打出套件名稱真的是有點麻煩,所以python有提供我們幫套件取綽號的語法喔。
import pandas as pd
白話一點就是把pandas引進來然後叫它pd,所以當我要使用pandas裡面的函式時,只需要打出pd.就可以了。以上就是套件引入的方式。
前天提到了數值、字串、串列、元祖跟字典這5種資料型態。基本上最簡單的就是數值跟字串,然後數值跟字串的組合可以變成串列或元組,一對一關係的資料可以變成字典。那如果我們想要有一個表格的話,應該怎麼辦呢?最陽春的方法就是在串列裡面放串列。
grades_list = [
[Amy, 90, 85],
[Andy, 60, 58],
[Brian, 50, 75]
]
print(grades_list)
# 輸出
[['Amy', 90, 85], ['Andy', 60, 58], ['Brian', 50, 75]]
這樣只要我們記住第一行代表人名,第二行代表數學成績,第三行代表英文成績就可以了。但是這個表格一看就很不直覺,而且萬一記錯行了不是很麻煩嗎?不然我們在字典裡面放串列好了。
grades_dict = {
"name": ["Amy", "Andy", "Brian"],
"math": [90, 60, 50],
"english": [85, 58, 75]
}
print(grades_dict)
# 輸出
{'name': ['Amy', 'Andy', 'Brian'], 'math': [90, 60, 50], 'english': [85, 58, 75]}
感覺還是不太對。如果你跟我一樣,想要的是那種一目瞭然的表格,那pandas絕對是你的最佳選擇。pandas裡面提供一種叫做Dataframe的二維資料型態,宣告之後長得就跟我們平常看到的表格一樣。接下來就跟大家介紹怎麼用pandas製作dataframe。
1️⃣轉換串列
df_from_list = pd.DataFrame(grades_list)
print(df_from_list)
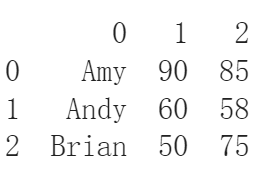
出來的結果就長這樣,感覺比較像表格了,但還是沒有每一行的名字誒,原來是有忘記填的參數啊,趕快加上去。
df_from_list = pd.DataFrame(grades_list, columns = ["Name", "Math_grade", "English_grade"])
print(df_from_list)
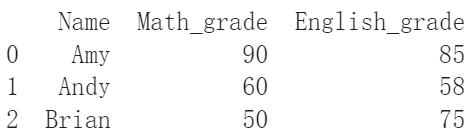
嗯嗯看起來終於是一個表格應該有的樣子了。
2️⃣轉換字典
df_from_dict = pd.DataFrame(grades_dict)
print(df_from_dict)
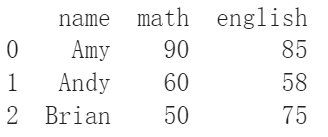
因為pandas會把字典裡面的key當成每一列的名字,所以不用特別再加什麼參數進去,超級方便。以上兩種自己建立表格的方法基本上就是看大家自己比較喜歡哪一種再選來用就好。如果是想從其他檔案裡面把表格引進python,當然也是沒有問題,只要照著下面的方法做就行。
3️⃣讀取外部檔案
因為最常見的表格形式是存在csv檔裡面,所以下面就示範怎麼把csv檔裡面的表格讀進python裡面。大家可以用這個檔案跟著一起做。
首先要把檔案傳到colab上面的資料夾裡。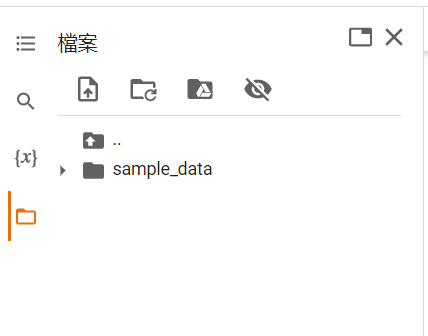
接下來點擊檔案旁邊的三個小點點複製檔案位置到read_csv()這個函式裡面就完成了。
data = pd.read_csv("/content/IMDB-Movie-Data.csv")
因為這個表格還滿巨大的,所以我們先不要把它印出來。等一下跟著pandas其他功能的介紹再慢慢看下去。
剛開始讀取表格進來以後,我們一定會想初步知道它的相關資訊嘛,這個時候就可以使用info()來看。
data.info()
# 輸出
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 1000 non-null int64
1 Title 1000 non-null object
2 Genre 1000 non-null object
3 Description 1000 non-null object
4 Director 1000 non-null object
5 Actors 1000 non-null object
6 Year 1000 non-null int64
7 Runtime (Minutes) 1000 non-null int64
8 Rating 1000 non-null float64
9 Votes 1000 non-null int64
10 Revenue (Millions) 872 non-null float64
11 Metascore 936 non-null float64
dtypes: float64(3), int64(4), object(5)
memory usage: 93.9+ KB
從第一行我們可以看到這是一個dataframe,第二跟第三行則是告訴我們這是一個12×1000的dataframe;再下面的表格則是列出了每一行的名稱、實際資料量(不是缺失值的儲存格數量)跟資料型態。
如果我們想要進一步看看裡面的資料到底長什麼樣子的話,可以使用head()來看前幾筆資料,或是用tail()來看後幾筆資料。(填入數字的話可以指定想看的數量,不填的話預設值是5)
data.head()
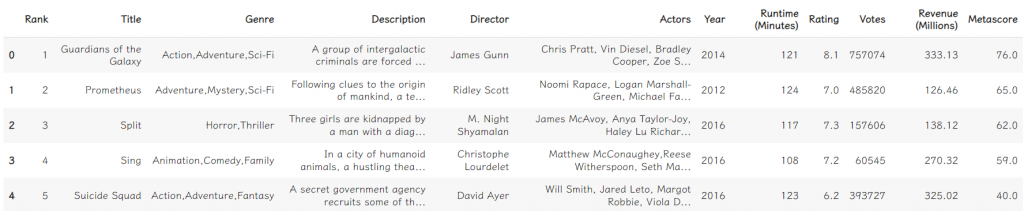
data.tail(2)

這樣大家應該能感受到pandas的重要性了吧,看起來真的不能再更舒服了。
如果想要看特定行(column)裡面的資料,可以使用[]包住那個行的名字,像下面這樣,產出的是一維陣列。
data["Title"].head()
# 輸出
0 Guardians of the Galaxy
1 Prometheus
2 Split
3 Sing
4 Suicide Squad
Name: Title, dtype: object
我們當然也可以看不只一行的資料,但是要注意的地方是,這裡必須使用雙重中括號[[]]才能得到二維dataframe的輸出。
data[["Title", "Year"]].head()
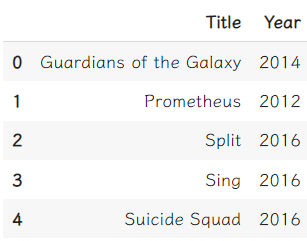
既然可以取得特定行的資料,當然也就可以取得特定列(row)的資料。一樣使用[],然後在裡面放入想要看的列索引值。如果想看的是連續的資料,用:區隔開始的數字跟結束的數字就行。
data[50:55]
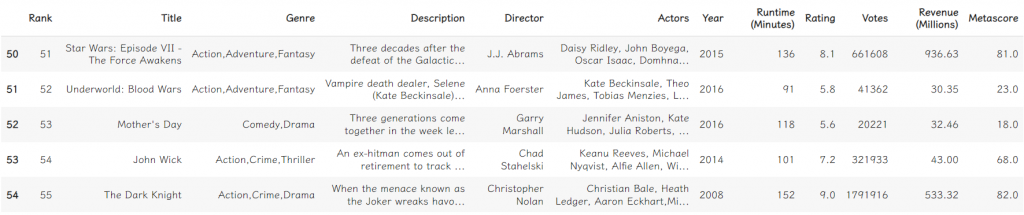
如果想要取得特定儲存格的值,可以運用at[]或是iat[]。使用at[]時要輸入列的索引值跟行的名字做為參數;iat[]則是需要列的索引值跟行的索引值作為參數。
print(data.at[0, "Genre"])
print(data.iat[0, 2])
# 輸出
"Action,Adventure,Sci-Fi"
"Action,Adventure,Sci-Fi"
比at[]跟iat[]更進階的,可以一次取出多個儲存格的方法是loc[]跟iloc[]。他們的用法基本上跟上面相同。
data.loc[[0, 50], ["Title", "Genre", "Year"]]

data.iloc[[0, 50], [1, 2, 6]]

如果想要修改dataframe裡面的資料要怎麼辦呢?很簡單,直接替代掉就可以了。例:Brian數學其實是考55分,不是50分。
df_from_dict.at[[2], ["math"]] = 55
print(df_from_dict)
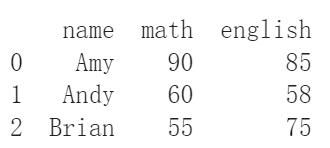
可以修改資料當然就可以增加資料。如果想要增加新的一行,可以直接宣告一行。
df_from_dict["chinese"] = [85, 50, 67]
print(df_from_dict)
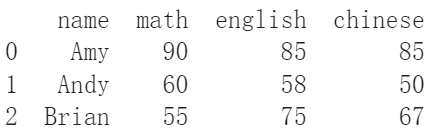
如果還想指定新的一行要插在哪裡的話,可以使用insert()這個函式。第一個參數填入希望這一行插在什麼位置,第二個參數填入新行的名字,第三個參數填入串列型態的資料。
df_from_dict.insert(1, column = "science", value = [100, 70, 68])
print(df_from_dict)
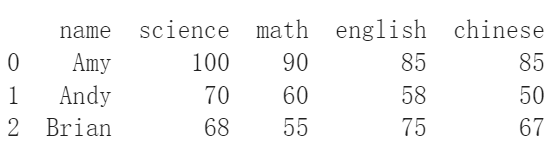
如果想加進去的是列的話,使用append()填入字典並把ignore_index這個參數設為True就可以了。
new_df = df_from_dict.append({
"name" : "Cindy",
"science" : 70,
"math" : 88,
"english" : 95,
"chinese" : 100
}, ignore_index=True)
print(new_df)
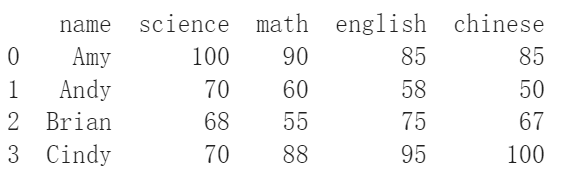
如果有想要刪除的資料,可以使用drop()。裡面會用到的參數有兩個,第一個寫出要刪除的行或列,第二個則是告訴pandas你要刪除的是行還是列。
df1 = new_df.drop(["science"], axis = 1) # 刪除名為science的行資料
df1 = df1.drop([0, 3], axis = 0) # 刪除第0列跟第3列資料
print(df1)

今天關於套件引入跟pandas的使用介紹就到這邊告一個段落。雖然量很大,看起來超難記住,但是之後做資料處理會一直用到,所以多練習才是最快熟悉的方法!(一時記不住也沒關係啦,反正文章可以一直回來看,用久了就記住了)明天會講超級重要的正歸表達式(Regular Expression),敬請期待。
最後一樣有函式統整表格(以下程式碼區塊之df接代指dataframe這個資料型態)
| 程式碼 | 功能 | 所需參數 | 備註 |
|---|---|---|---|
pd.DataFrame() |
生成dataframe | 串列或字典 | |
pd.read_csv() |
讀取csv檔中的表格 | 檔案位置 | |
df.head() |
讀取dataframe的前幾筆資料 | 想讀取的資料數 | 預設為5 |
df.tail() |
讀取dataframe的倒數幾筆資料 | 想讀取的資料數 | 預設為5 |
df[] |
讀取dataframe中的指定行(column) | 想讀取的行名 | 回傳series |
df[[]] |
讀取dataframe中的指定數行(column) | 想讀取的行名 | 回傳dataframe |
df[a:b] |
讀取dataframe中索引值a到b的列 | 想讀取的列索引值範圍 | 回傳dataframe |
df.at[] |
讀取dataframe內特定儲存格資料 | 列索引值, 行名 | |
df.iat[] |
讀取dataframe內特定儲存格資料 | 列索引值, 行索引值 | |
df.loc[] |
讀取dataframe內數個特定儲存格資料 | 列索引值串列, 行名串列 | |
df.iloc[] |
讀取dataframe內數個特定儲存格資料 | 列索引值串列, 行索引值串列 | |
df.insert() |
將新的一行插入dataframe中指定位置 | 插入位置索引值, column = 行名, value = 資料串列 | |
df.append() |
將新的一列插入dataframe | 包含列內容之字典, ignore_index=True | 回傳新dataframe |
df.drop() |
刪除dataframe裡的特定行 | 包含欲刪除行名之串列, axis = 1 | 回傳新dataframe |
df.drop() |
刪除dataframe裡的特定列 | 包含欲刪除行名之串列, axis = 0 | 回傳新dataframe |

